Contextual Retrieval RAG


Wenn du meinen Blog regelmäßig verfolgst, weißt du: Das ist bereits das dritte Mal, dass wir uns mit Retrieval-Augmented Generation (RAG) beschäftigen – und diesmal geht es nicht nur um kleine Stellschrauben, sondern um eine architektonische Optimierung, die die Suche in deinem Wissensbestand grundlegend präziser macht: Contextual Retrieval. In diesem Beitrag erkläre ich dir im Detail, wie das funktioniert, warum es so effektiv ist und wie du es in n8n umsetzt.
Warum wir RAG zum dritten Mal optimieren
Du kennst RAG inzwischen in- und auswendig – die Aufteilung in Chunks, das Erzeugen von Embeddings, die semantische Suche im Vektor-Store. Doch trotz aller Verbesserungen fehlt es klassischen RAG-Systemen oft an Kontext: Einzelne Textstellen sind isoliert zu kurz, um wirklich präzise Antworten zu ermöglichen. Genau hier setzt Contextual Retrieval an – eine Architekturänderung im Preprocessing, die jedem Chunk seine Rolle im Gesamtdokument erklärt und so die Treffergenauigkeit um fast 50 % steigert. (Quelle: Anthropic)
Das Problem bei traditionellem RAG
- Chunking ohne Kontext
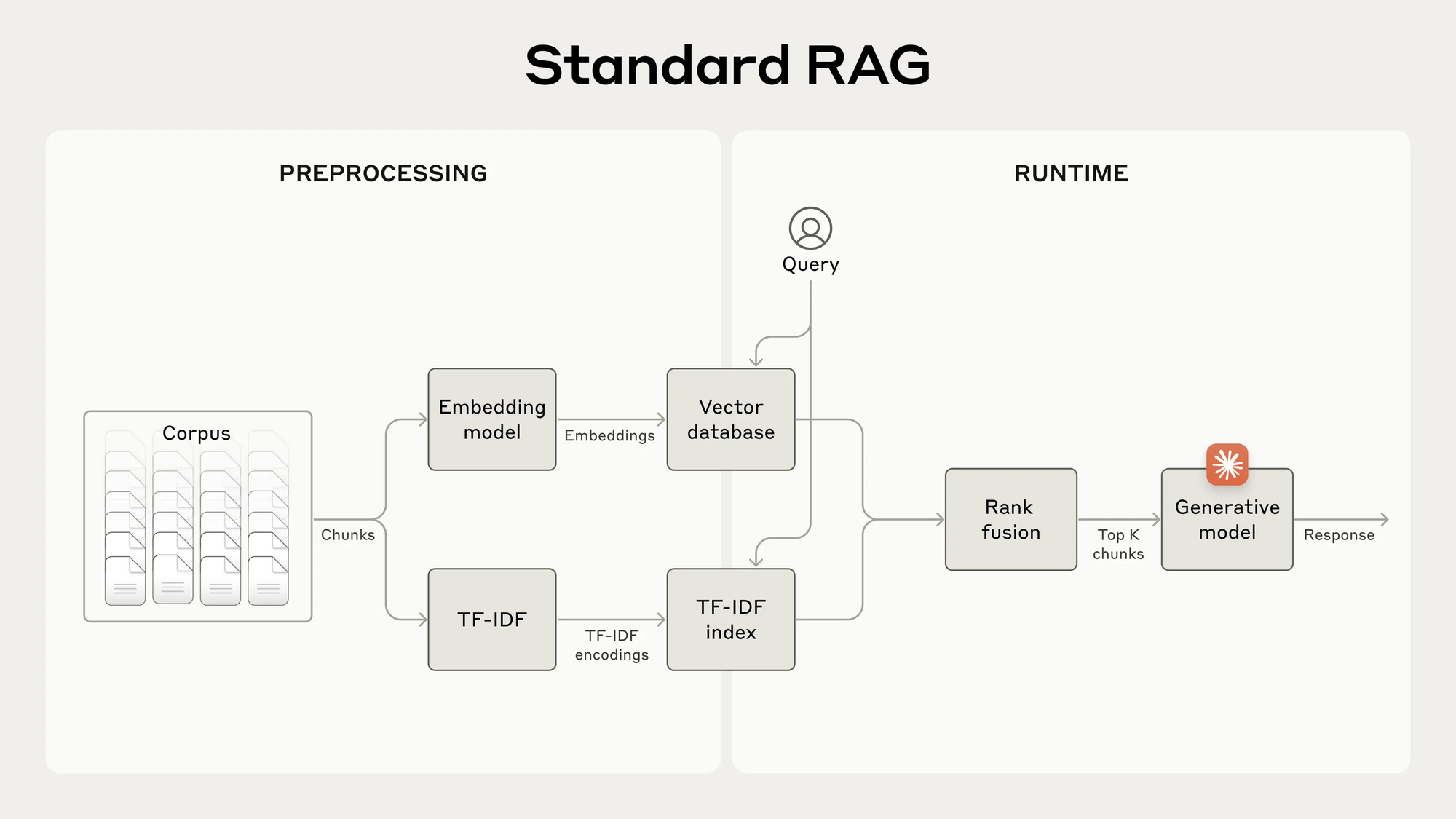
Große Dokumente werden in Abschnitte (Chunks) von z. B. 200–400 Tokens aufgeteilt. Jeder Chunk wird in einen Vektor transformiert und in der Datenbank gespeichert. - Semantische Suche
Bei einer Nutzeranfrage erzeugt das System ein Query-Embedding und findet die ähnlichsten Chunks per Vektorsuche. - Fehlende Präzision
Oft fehlen exakte Details (z. B. Firmennamen, Zeiträume), sodass relevante Chunks nicht erkannt werden oder die KI nicht weiß, wie sie den Inhalt einordnen soll. In Tests lag die Fehlerrate so bei knapp 10 %.
(Quelle: Anthropic)
Contextual Retrieval: Architektur auf den Punkt
Contextual Retrieval kombiniert zwei Sub-Techniken:
- Contextual Embeddings
- Contextual BM25
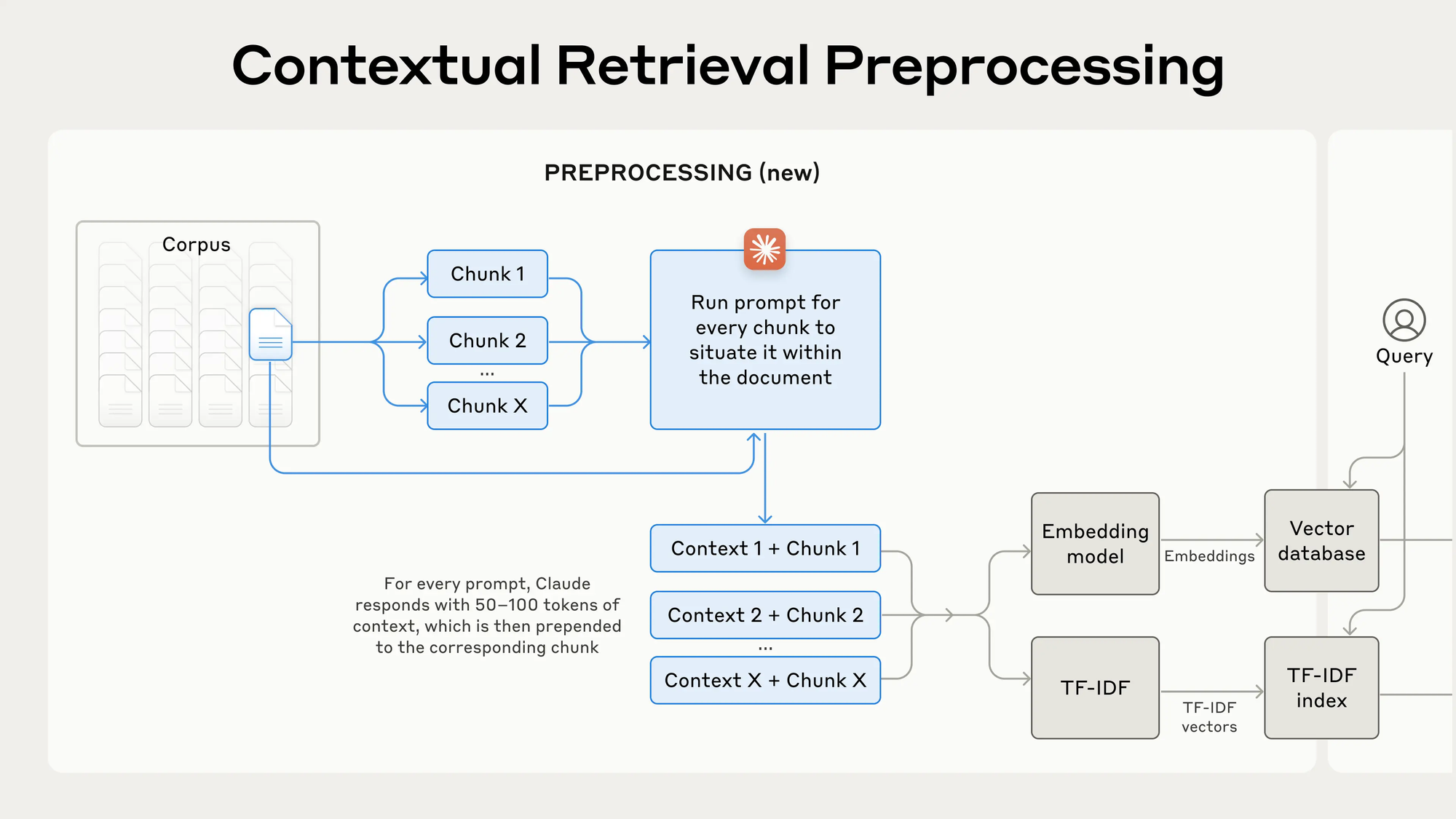
1. Contextual Embeddings
Für jeden Chunk generierst du mittels eines kleinen LLMs (z. B. GPT-4.1 Nano oder Claude 3 Haiku) einen kurzen Kontext. Der Prompt sieht so aus:
<document>
[GESAMTEDOKUMENT]
</document>
Hier ist das Chunk, das du einordnen sollst:
<chunk>
[CHUNK-INHALT]
</chunk>
Gib mir in 1–2 Sätzen eine prägnante Einordnung, wo dieses Chunk im Dokument steht und worum es geht.Das Ergebnis (50–100 Token) wird vor dem eigentlichen Chunk eingefügt, getrennt durch ---:
Dies ist ein Abschnitt aus dem Q2-Bericht 2023, der den Umsatz um 3 % gegenüber dem Vorquartal beschreibt.
---
The company's revenue grew by 3% over the previous quarter.2. Contextual BM25
Parallel zur Vektorsuche baust du einen BM25-Index auf den kontextualisierten Chunks auf. BM25 fängt exakte Suchbegriffe ein (z. B. „TS-999“) und ergänzt so die semantische Suche.
Quelle: Anthropic
Performance-Gewinne durch Contextual Embeddings & BM25
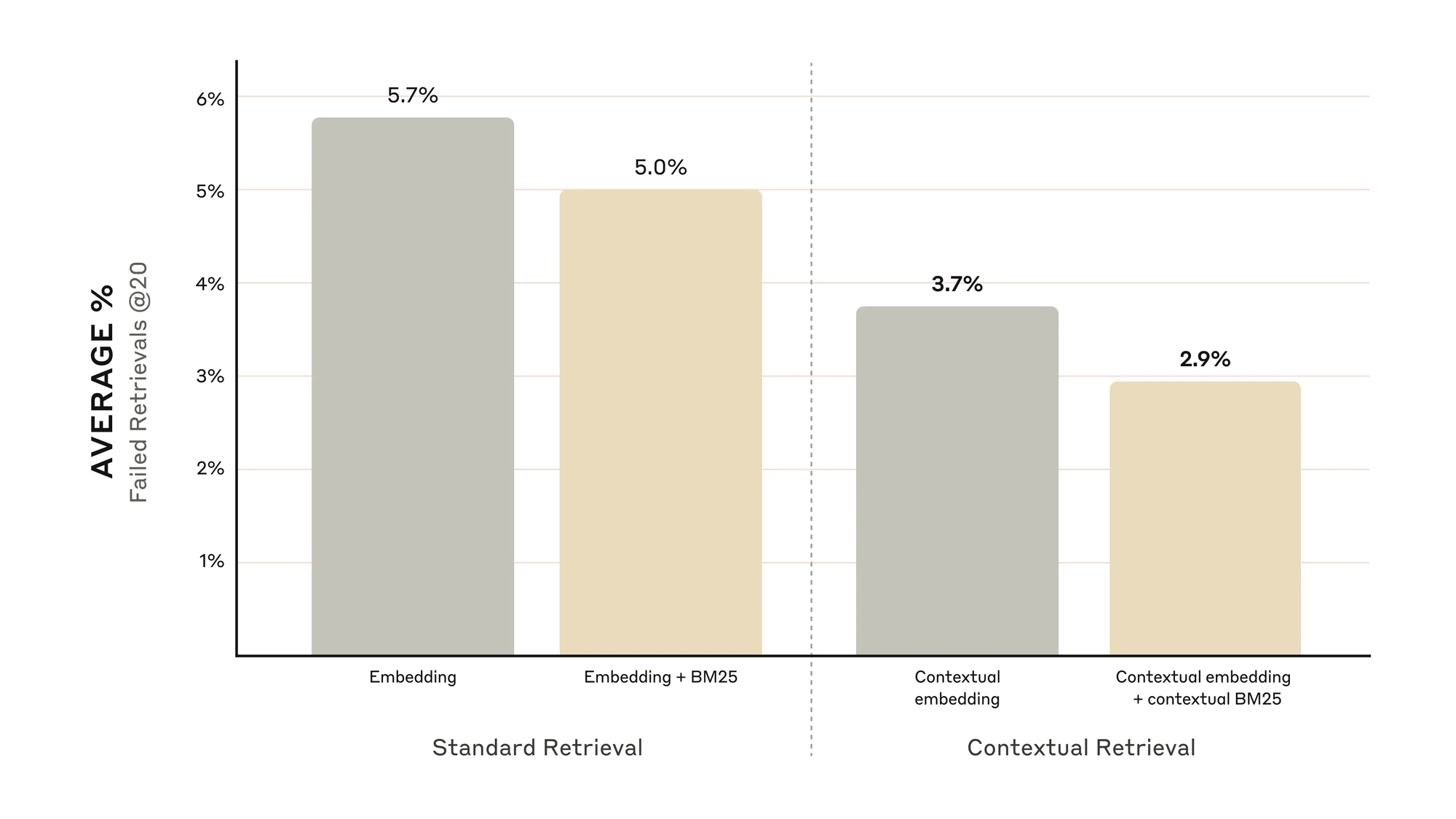
Anthropics Tests über verschiedene Domänen hinweg zeigen beeindruckende Ergebnisse:
- Nur Embeddings: Recall-Fail @20 = 5,7 %
- + Contextual Embeddings: Recall-Fail @20 = 3,7 % (−35 %)
- + Contextual BM25: Recall-Fail @20 = 2,9 % (−49 %)
Quelle: Anthropic
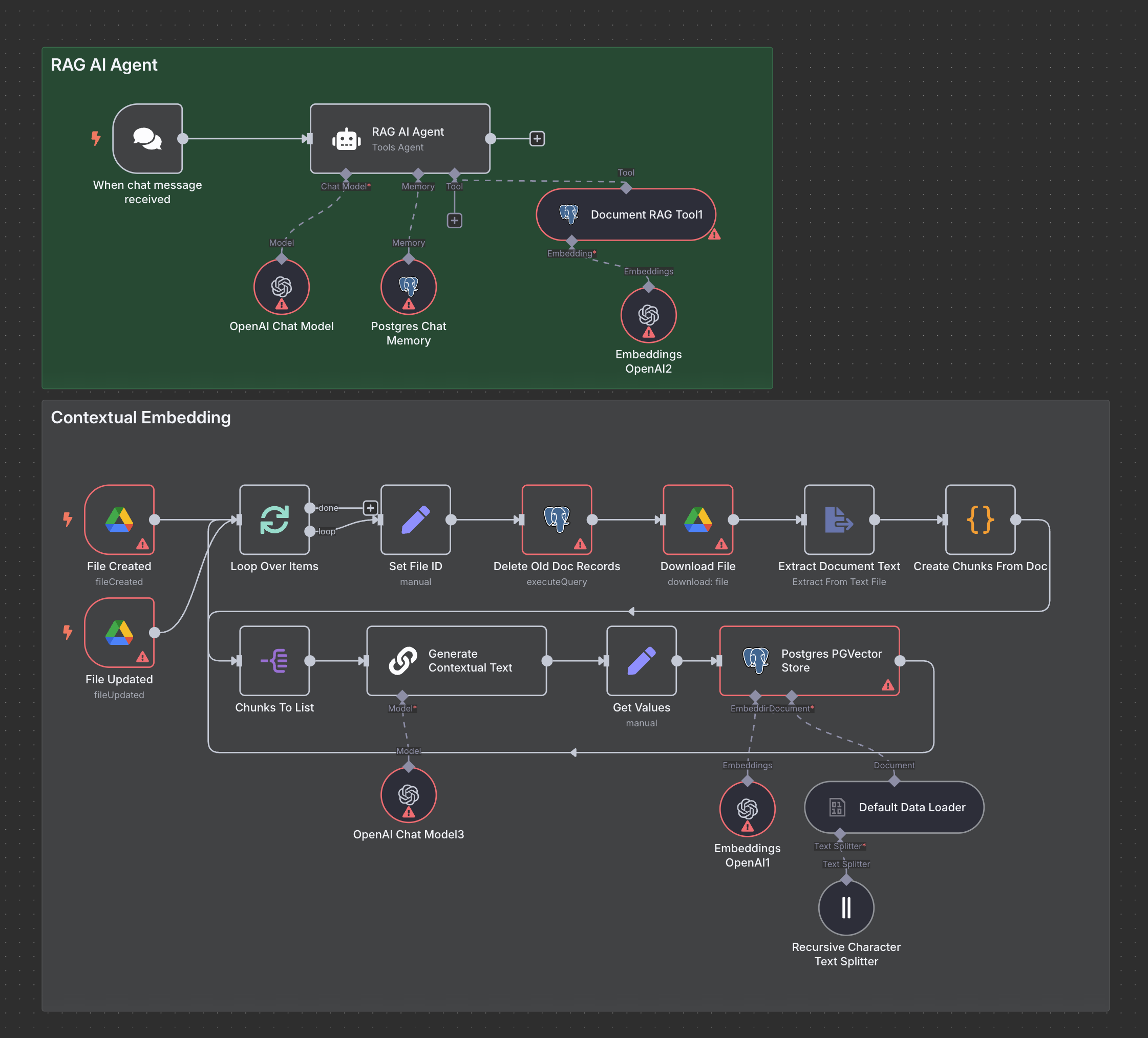
Praktische Umsetzung in n8n
- Trigger: Node überwacht einen Ordner.
- Text-Extraktion: PDF- oder Docs-Parser-Nodes ziehen den reinen Text.
- Custom Chunking: JavaScript-Node splittet bei 400 Zeichen (kein Overlap).
- Loop: Jeder Chunk durchläuft einzeln den Workflow.
- Prüfung ob bereits vorhanden - löschen und neuschreiben
- LLM-Aufruf: GPT-4.1 Nano + Prompt Caching (bis zu −90 % Kosten) generiert den Kontext.
- Zusammenfügen:
Context + --- + Chunk. - Embedding: Embedding-Node mit demselben Modell wie dein Agent.
Speichern: Neon/Supabase-Node schreibt Vektor + Metadaten (Datei-ID, Titel, URL).
Deep Dive: Kosten, Modelle & Prompt Caching
- Modellwahl: GPT-4 Nano oder Claude 3 Haiku reichen für Contextual Embeddings / Alternativ: lokale Embedding Modelle
- Prompt Caching: Einmaliges Übergeben des Dokuments, danach nur noch Verweise – OpenAI ~50 % Rabatt, Anthropic/Gemini ~90 %.
- Kostenrechnung (800 Token Chunks, 8 k Dokument, 100 Token Kontext): ≈ 1 $ pro Million Token.
So bleibt dein System auch in großem Maßstab bezahlbar.
Ausblick: Reranking & weiterführende Techniken
- Reranking: Initiale Top-150 via RAG holen, dann per spezialisierter Reranker (z. B. Cohere) auf Top-20 reduzieren – Recall-Fail ∼1,9 % (−67 %).
- Query Expansion: Automatische Synonym-Erweiterungen aus Glossaren.
- Genetische RAG: Evolutionäre Optimierung der Chunk-Auswahl.
Diese Techniken lassen sich nahtlos ergänzen – in n8n über zusätzliche Nodes.
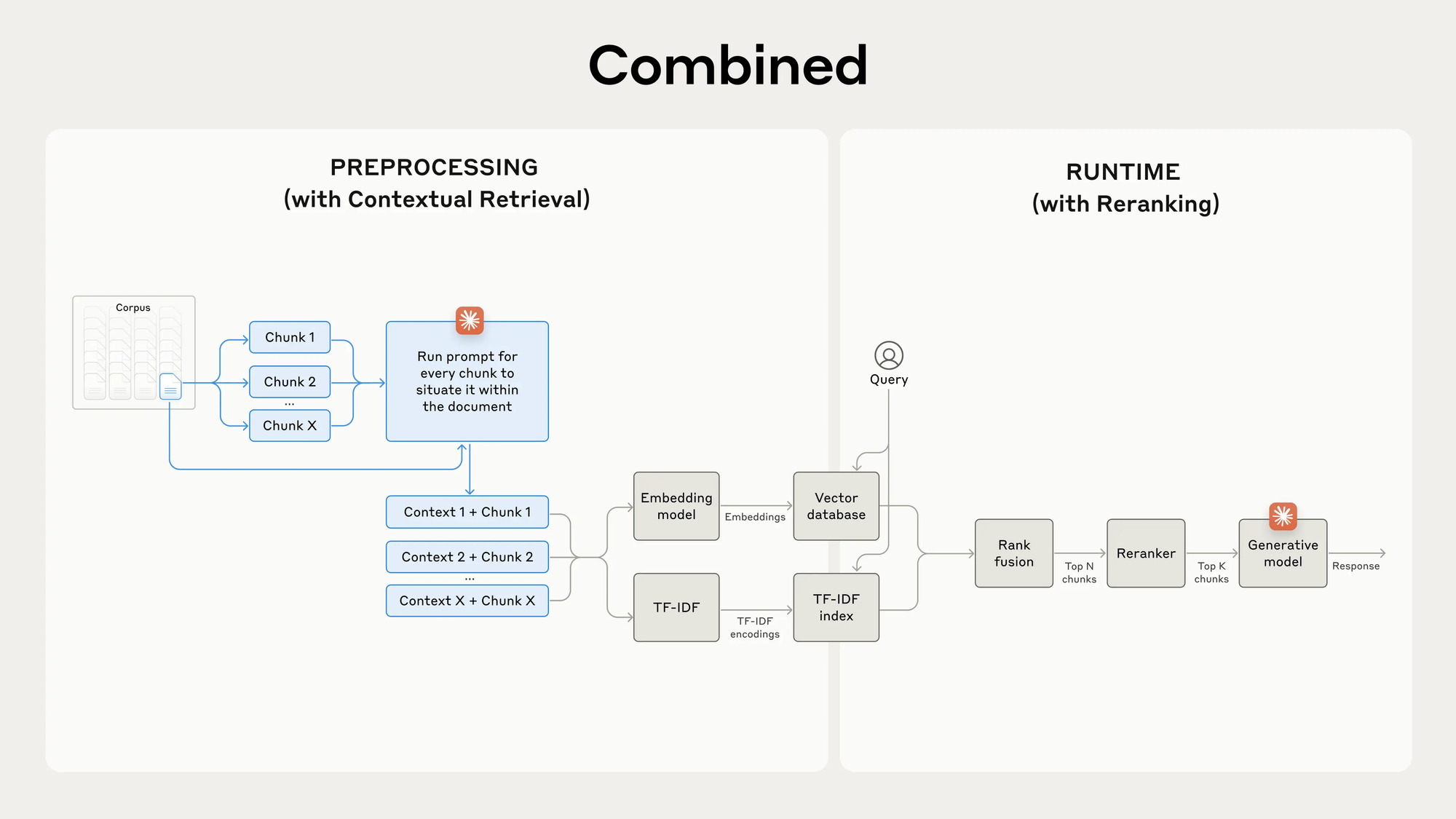
Quelle: Anthropic
Fazit
Mit Contextual Retrieval änderst du nicht nur eine Zahl in deiner Pipeline, sondern die gesamte Architektur deines RAG-Systems. Indem du jedem Chunk erklärst, wo es herkommt und warum es relevant ist, senkst du die Fehlerrate von rund 10 % auf unter 3 %. Ob du das visuell in n8n aufsetzt oder zukünftig in anderen Tools programmierst – die Prinzipien bleiben gleich:
- Kontext erzeugen
- Semantisch + lexikalisch suchen
- Reranken (optional)
Man kann sich das Ganze auch bildlich vorstellen, als würdest du jedem Buch in deinem Regal einen kleinen Notizzettel anheften, der dir kurz den Inhalt und Kontext verrät – so findest du jederzeit genau, was du suchst.
Mach den nächsten Schritt in deiner RAG-Reise und überzeuge dich selbst von der Präzision von Contextual Retrieval!