Intelligenter suchen, bessere Antworten: Das neue Hybrid-Retrieval in HIVE

Wie wir durch die Kombination verschiedener Suchmethoden die Qualität unserer KI-Assistenz deutlich verbessert haben
Was hat sich geändert?
Kurz gesagt: HIVE findet jetzt relevante Dokumente zuverlässiger – und das merkt man direkt an der Antwortqualität.
Das Problem vorher: Du suchst nach „Betriebsratswahl”. Eine klassische Stichwortsuche findet alle Dokumente mit genau diesem Wort. Eine semantische Suche (Vektorsuche) versteht auch, dass „Personalvertretung” oder „Arbeitnehmervertretung wählen” thematisch passen – selbst ohne das exakte Stichwort.
Bisher hat HIVE erst eine Suche durchgeführt und die Ergebnisse dann mit einem „Reranker” neu sortiert. Funktionierte gut, hatte aber einen Haken: Wenn die erste Suche ein relevantes Dokument nicht gefunden hatte, konnte auch der Reranker nichts mehr retten.
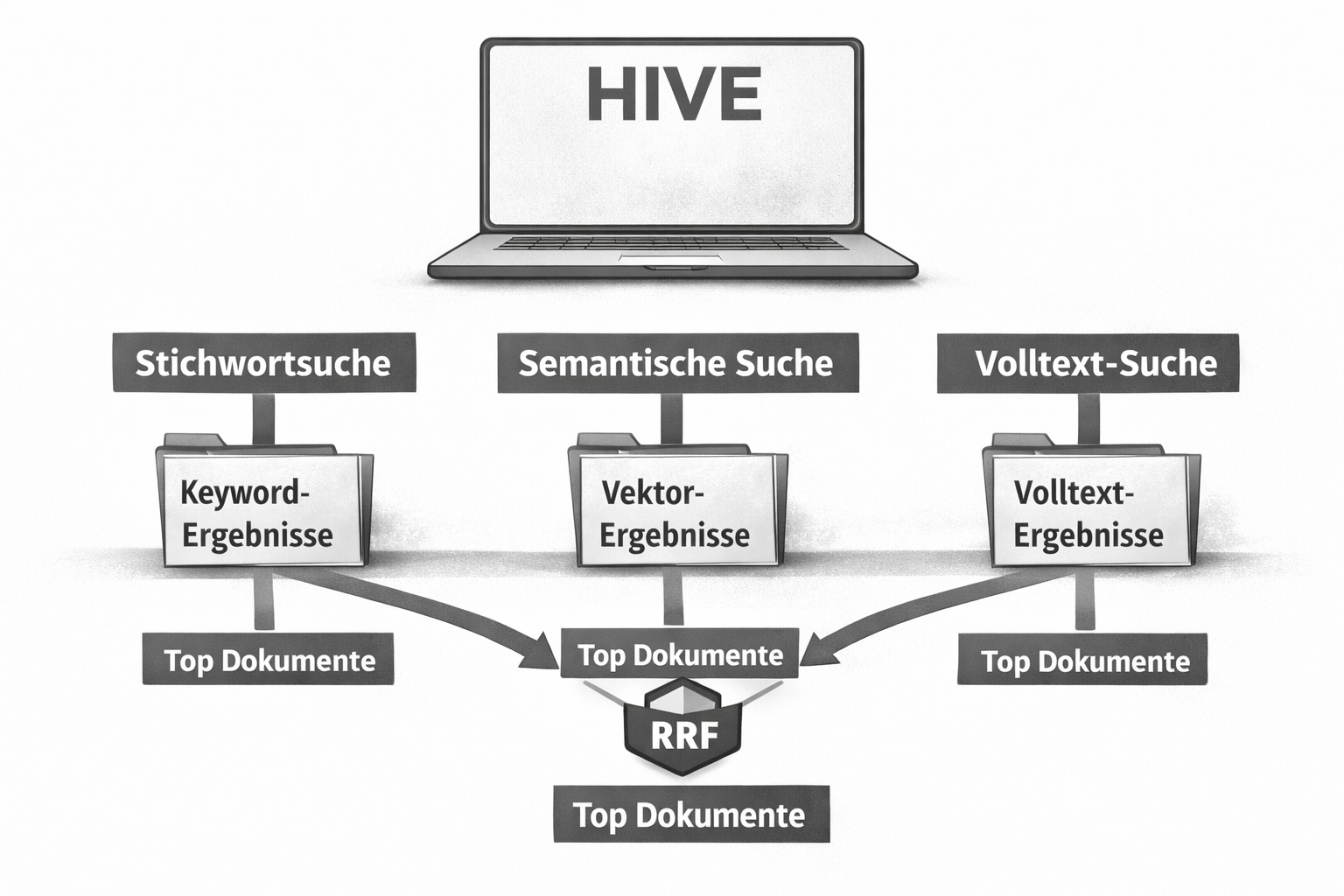
Jetzt läuft das anders: Mehrere verschiedene Suchmethoden arbeiten parallel und ihre Ergebnisse werden intelligent kombiniert – mit einem Verfahren namens Reciprocal Rank Fusion (RRF).
Die Bibliotheks-Analogie
Du brauchst alles zum Thema „Tomaten anbauen” und hast drei Helfer:
Helfer 1 (Stichwortsuche) durchforstet den Katalog nach exakten Begriffen. Findet alle Dokumente mit „Tomaten” und „anbauen” – super präzise. Aber das Kapitel „Nachtschattengewächse im Gewächshaus” geht ihm durch, weil es andere Worte verwendet.
Helfer 2 (Semantische Suche) versteht Bedeutungen. Findet auch „Nachtschattengewächse im Gewächshaus” und sogar „Paradeiser kultivieren”. Manchmal empfiehlt er aber auch Dokumente über Paprika, die nur am Rande passen.
Helfer 3 (Volltext-Suche) ist der Spezialist für Sortennamen wie „San Marzano” oder „Ochsenherz”, die die anderen übersehen.
Das alte System hätte nur einen Helfer gefragt und dann versucht, seine Empfehlungen nachträglich zu optimieren. Das neue System fragt alle drei gleichzeitig und kombiniert deren Wissen intelligent.
RRF: Das Wahlsystem für Suchergebnisse
Die Kombination funktioniert mit Reciprocal Rank Fusion (RRF) – im Prinzip wie eine Oscar-Wahl.
Jede Suchmethode erstellt ihre eigene Rangliste. RRF wertet das so aus:
- Ein Dokument bekommt Punkte basierend auf seiner Position in jeder Liste
- Platz 1 gibt mehr Punkte als Platz 10
- Dokumente, die in mehreren Listen weit oben stehen, sammeln die meisten Punkte
Der Clou: Der Unterschied zwischen Platz 1 und 2 zählt mehr als zwischen Platz 50 und 51. Das spiegelt wider, wie Relevanz in der Praxis funktioniert – die Top-Ergebnisse sind meistens deutlich besser als der Rest.
Kurzes Beispiel
Du suchst nach „Urlaubsantrag”:
| Dokument | Rang Stichwort-Suche | Rang Semantische Suche |
|---|---|---|
| Urlaubsrichtlinie | 1 | 3 |
| Antragsformular Urlaub | 2 | 1 |
| Arbeitszeitregelung | 4 | 2 |
| Personalhandbuch | 3 | 8 |
„Antragsformular Urlaub” steht in beiden Listen weit oben → gewinnt die kombinierte Rangliste. Die „Urlaubsrichtlinie” folgt dicht dahinter (Platz 1 bei Stichwortsuche bringt ordentlich Punkte).
Was bringt dir das konkret?
Weniger „Das weiß ich nicht”-Antworten
Wenn ein relevantes Dokument existiert, findet es mindestens eine der Suchmethoden. Dass alle drei ein wichtiges Dokument übersehen – unwahrscheinlich.
Fachbegriffe und Alltagssprache? Egal.
Suchst du nach „BDSG” oder nach „Datenschutzgesetz”? Nach „KVP” oder „kontinuierliche Verbesserung”? Das neue System findet die Dokumente, egal wie du fragst.
Robustere Ergebnisse
Jede Suchmethode hat Schwächen. Stichwortsuche scheitert bei Synonymen, semantische Suche kann zu vage werden. Durch die Kombination gleichen sich die Schwächen aus.
Funktioniert sofort
Ein großer praktischer Vorteil: RRF braucht kein aufwändiges Tuning. Es funktioniert out-of-the-box – egal ob Rechtsabteilung, IT oder Produktion.
Alte vs. neue Methode
| Aspekt | Alte Methode (BM25 + Reranker) | Neue Methode (Hybrid + RRF) |
|---|---|---|
| Suchansätze | Einer, nachträglich optimiert | Mehrere parallel |
| Fehlertoleranz | Erste Suche versagt → Reranker hilflos | Methoden kompensieren sich gegenseitig |
| Geschwindigkeit | Schnell | Sehr schnell (parallel) |
| Anpassungsbedarf | Reranker braucht Feintuning | Funktioniert ohne Kalibrierung |
| Ressourcen | Reranker-Modelle sind rechenintensiv | Effizienter |
Fazit
Das neue Hybrid-System macht HIVE zu einem zuverlässigeren Wissensassistenten. Relevante Dokumente werden besser gefunden, die Antwortqualität steigt – und das Ganze funktioniert sowohl mit Fachsprache als auch mit alltäglichen Beschreibungen.
Technischer Deep-Dive
Für alle, die wissen wollen, wie es unter der Haube funktioniert.
Die Architektur
Drei Retrieval-Strategien laufen parallel auf jede Anfrage:
1. Dense Vector Search (Semantische Suche)
- Embedding-Modelle vektorisieren Dokumente und Queries
- Ähnlichkeit über Cosinus-Distanz im hochdimensionalen Raum
- Stärke: Synonyme, konzeptuelle Ähnlichkeiten
2. BM25 (Sparse Vector / Keyword Search)
- Best Match 25 – TF-IDF-Weiterentwicklung mit Längen-Normalisierung
- Score basiert auf Termfrequenz × inverse Dokumentfrequenz
- Stärke: Exakte Matches, Fachbegriffe, Abkürzungen
3. Full-Text Search
- Phrasen-Queries, spezifische Zeichenketten
- Wichtig für Modellbezeichnungen, Artikelnummern, mehrsprachige Inhalte
- Kompensiert Sparse-Vector-Limitierungen (~30k Dimensionen decken nicht alle Keywords ab)
Die RRF-Formel
RRF_Score(d) = Σ 1 / (k + rank_i(d))
d= Dokumentk= Glättungsparameter (Standard: 60)rank_i(d)= Position des Dokuments in Ergebnisliste i- Summe über alle Suchmethoden, in denen das Dokument vorkommt
Warum k = 60?
Empirisch ermittelt (Cormack et al., 2009). Der Parameter balanciert den Einfluss der Rangposition:
- Rang 1 → Score 1/61 ≈ 0.0164
- Rang 2 → Score 1/62 ≈ 0.0161
- Unterschiede bei hohen Rängen signifikanter als bei niedrigen
Gewichtete Variante
Für Szenarien mit Priorisierung (z.B. 70% semantisch, 30% keyword):
wRRF_Score(d) = Σ w_i * 1 / (k + rank_i(d))
Warum RRF statt Reranker?
Das Reranker-Paradigma
Klassische Pipeline:
Query → BM25 (Top-K Kandidaten) → Cross-Encoder Reranking → Finale Ergebnisse
Cross-Encoder Reranker (BGE-Reranker, Cohere Rerank) bewerten Query-Dokument-Paare direkt via Transformer. Semantisch präzise, aber:
- Rechenintensiv: Jedes Dokument einzeln durch das Modell
- Latenz: GPU-Inferenz skaliert linear mit n Dokumenten
- Single Point of Failure: BM25 findet Dokument nicht → Reranker kann es nicht retten
RRF-Vorteile
| Aspekt | Cross-Encoder Reranker | Reciprocal Rank Fusion |
|---|---|---|
| Latenz | O(n) GPU-Inferenzen | Simples Score-Merging |
| Hardware | GPU erforderlich | CPU reicht |
| Kalibrierung | Modell-spezifisches Fine-Tuning | Parameter-frei (k=60 universell) |
| Score-Kompatibilität | Verschiedene Retriever = inkompatible Scores | Rangbasiert – Score-Skalen egal |
| Outlier-Robustheit | Extreme Scores verzerren Ergebnisse | Rang-basiert, ignoriert Score-Magnitude |
Was die Studien sagen
- Hybrid Search mit RRF übertrifft konsistent reine Vector- oder Keyword-Suche
- Three-Way Retrieval (BM25 + Dense Vectors + Full-Text) ist optimal für RAG (IBM Research)
- RRF erreicht ohne Tuning 85-95% der Performance von aufwändig kalibrierten Weighted-Score-Methoden
Implementierung
Warum RRF Score-Normalisierung überflüssig macht
Bei Score-basierten Fusion-Methoden (Weighted Sum) müssen unterschiedliche Skalen normalisiert werden:
- Cosine Similarity: [0, 1] oder [-1, 1]
- BM25: unbegrenzt, typisch [0, 30]
- Full-Text: variabel
Min-Max oder L2-Normalisierung hat Probleme:
- Outlier verzerren die Skalierung
- Verschiedene Query-Typen → verschiedene Verteilungen
RRF umgeht das komplett durch ausschließliche Nutzung von Rangpositionen.
Fazit
Hybrid-Retrieval mit RRF bietet die optimale Balance:
- Qualität: Komplementäre Suchmethoden gleichen Schwächen aus
- Robustheit: Keine Kalibrierung nötig, stabil über verschiedene Domänen
- Effizienz: Weniger Hardware als GPU-basierte Reranker bei vergleichbarer Qualität
- Skalierbarkeit: Parallele Ausführung = niedrige Latenzen auch bei großen Wissensbasen
Referenzen
- Cormack, G. V., Clarke, C. L., & Buettcher, S. (2009). Reciprocal rank fusion outperforms Condorcet and individual rank learning methods. SIGIR ’09.
- IBM Research (2024). Blended RAG: Combining BM25, Dense Vectors, and Sparse Vectors for optimal retrieval.
- OpenSearch (2025). Introducing reciprocal rank fusion for hybrid search.
- Weaviate Documentation. Hybrid Search Explained.
- Azure AI Search Documentation. Hybrid search scoring with RRF.
Fragen zur technischen Umsetzung? Melde dich bei uns für eine individuelle Beratung.