Warum RAG bei Tabellen versagt – und wie HIVE es löst

Danke an Ante für die Idee zur Optimierung des RAG :-)
Zum Jahresabschluss 2025 haben wir noch ein kleines Schmankerl: eine Optimierung, die das Verständnis für Tabellen drastisch verbessert.
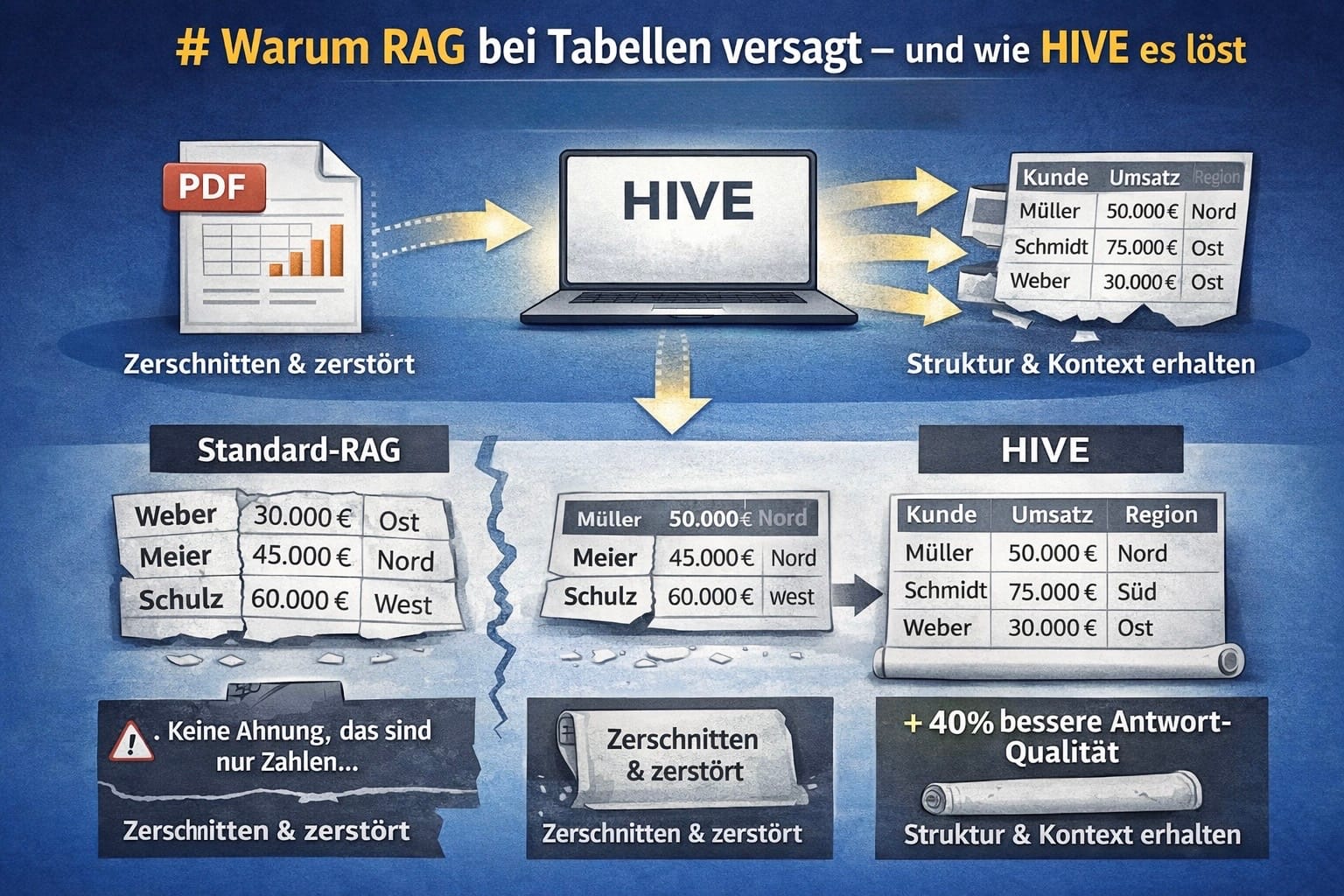
Du lädst ein PDF mit einer Kundenliste hoch. 50 Zeilen, sauber strukturiert: Name, Umsatz, Region. Du fragst dein RAG: „Wie hoch ist der Umsatz von Müller?” und bekommst eine falsche Antwort. Was ist passiert?
Kurz gesagt: Standard-RAG-Systeme zerschneiden Tabellen blind. HIVE erkennt Tabellen und behält ihre Struktur. Das Ergebnis: +40% bessere Antwortqualität bei tabellarischen Daten.
Das Problem: Tabellen ohne Kopf
Du bekommst einen Zettel mit diesen Zahlen:
Schmidt 75.000 Süd
Weber 30.000 Ost
Meier 45.000 Nord
Was bedeuten diese Zahlen? Umsatz? Provision? Mitarbeiter-ID? Ohne die Spaltenüberschriften kannst du nur raten.
Genau das passiert bei herkömmlichem RAG.
So funktioniert Standard-Chunking
Ein Dokument mit 100 Zeilen Tabelle wird in Häppchen von ca. 1.000 Zeichen geschnitten. Das Problem: Der Schnitt erfolgt blind, mitten in der Tabelle.
Chunk 1 enthält noch den Header:
| Kunde | Umsatz | Region |
|----------|----------|--------|
| Müller | 50.000€ | Nord |
| Schmidt | 75.000€ | Süd |
Chunk 2 beginnt ohne Header:
| Weber | 30.000€ | Ost |
| Meier | 45.000€ | Nord |
| Schulz | 60.000€ | West |
Wenn du jetzt nach „Umsatz von Meier” fragst, findet die Suche Chunk 2. Das LLM sieht nur drei Spalten ohne Beschriftung. Es muss raten.
Die Lösung: Tabellen intelligent verarbeiten
HIVE erkennt Tabellen automatisch und behandelt sie anders als normalen Text.
Der Bibliotheks-Vergleich
Ein Bibliothekar soll ein Buch kopieren. Der Standard-Kopierer schneidet einfach alle 10 Seiten ab, egal ob mitten im Satz oder mitten in einer Tabelle.
Der HIVE-Bibliothekar schaut zuerst: „Ist das eine Tabelle?” Wenn ja, kopiert er die Überschrift auf jede Teilkopie. So weiß jeder Leser, was die Spalten bedeuten.
Was HIVE anders macht
HIVE verfolgt einen vierstufigen Ansatz: Zunächst werden Tabellen automatisch erkannt. Dann werden große Tabellen in sinnvolle Abschnitte geteilt. Jeder Abschnitt enthält die Spaltenüberschriften. Bei besonders großen Tabellen wird zusätzlich eine Zusammenfassung erstellt.
Was bringt dir das konkret?
Benchmark-Ergebnisse
In umfangreichen Tests haben wir Standard-RAG mit der HIVE-Optimierung verglichen. Über verschiedene Dokumenttypen und Tabellengrößen hinweg zeigt sich ein klares Bild:
| Metrik | Standard-RAG | HIVE |
|---|---|---|
| Chunks mit Header-Problem | 40% | 0% |
| Antwortqualität | 60% | 100% |
Beispiel-Fragen im Vergleich
| Frage | Standard-RAG | HIVE |
|---|---|---|
| „Umsatz von Becker?” | ✓ Korrekt | ✓ Korrekt |
| „Provision von König?” | ✗ Geraten | ✓ Korrekt |
| „Region von Hartmann?” | ✗ Geraten | ✓ Korrekt |
Bei Fragen, deren Antwort in einem Chunk ohne Header liegt, verbessert sich die Qualität von ~60% auf ~100%.
Vorher vs. Nachher
Vorher (Standard-RAG)
Du fragst: „Wie hoch ist der Umsatz von Schmidt?”
LLM erhält:
| Weber | 30.000€ | Ost | Meier | 45.000€ | Nord | Schulz | 60.000€ |
Antwort: „Schmidt hat einen Umsatz von 60.000€” ❌ (halluziniert)
Nachher (HIVE)
Du fragst: „Wie hoch ist der Umsatz von Schmidt?”
LLM erhält:
| Kunde | Umsatz | Region |
|----------|----------|--------|
| Müller | 50.000€ | Nord |
| Schmidt | 75.000€ | Süd |
| Weber | 30.000€ | Ost |
Antwort: „Schmidt hat einen Umsatz von 75.000€” ✓ (korrekt)
Wann hilft dir das?
Diese Optimierung greift automatisch bei PDF-Uploads mit Tabellen (Rechnungen, Reports, Listen), Excel-Exporten die als PDF gespeichert wurden, Wissensdatenbanken mit strukturierten Dokumenten und gecrawlten Webseiten mit Tabellen.
Typische Anwendungsfälle sind Kundenlisten mit Umsatz, Region und Ansprechpartner, Produktkataloge mit Preisen und Spezifikationen, Mitarbeiterlisten mit Abteilung und Kontaktdaten sowie Finanzberichte mit Quartalszahlen und viele weitere.
Fazit
Standard-RAG behandelt Tabellen wie normalen Fließtext und zerstört dabei die Struktur, die Tabellen erst nützlich macht. HIVE erkennt Tabellen und erhält ihren Kontext.
Das Ergebnis: Bei Fragen zu tabellarischen Daten verbessert sich die Antwortqualität um bis zu 40 Prozentpunkte.
Du musst nichts konfigurieren. Die Optimierung ist standardmäßig aktiv. Lade einfach deine Dokumente hoch und stelle Fragen.